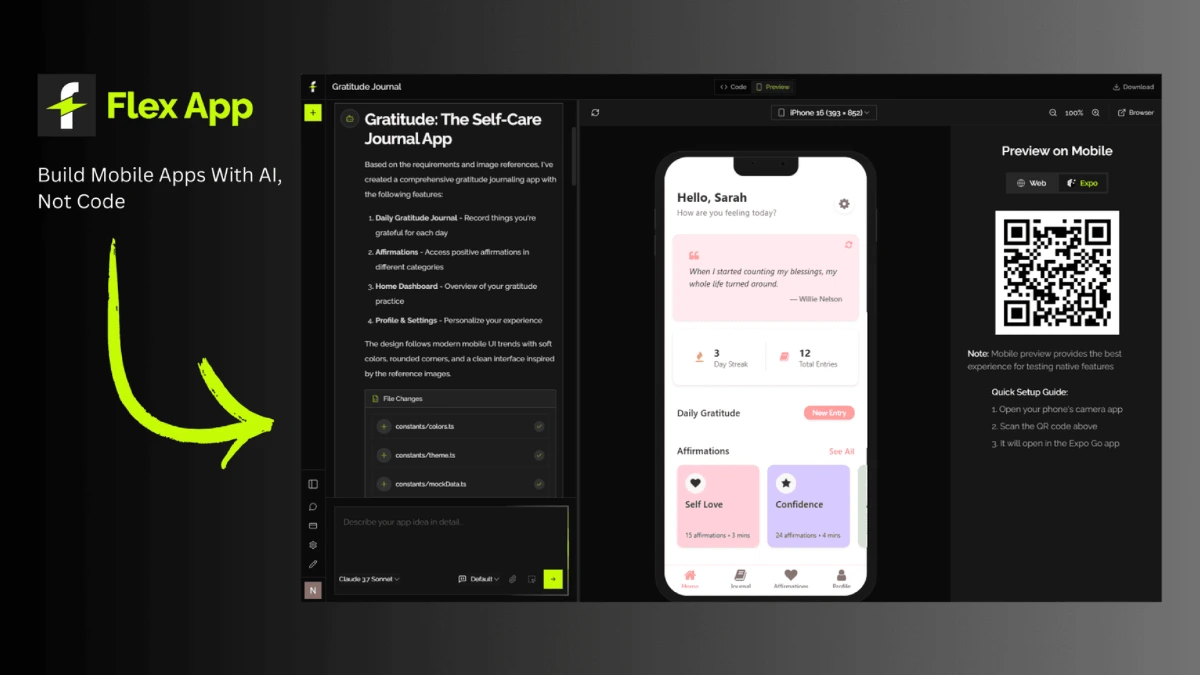
What is Lucebox?
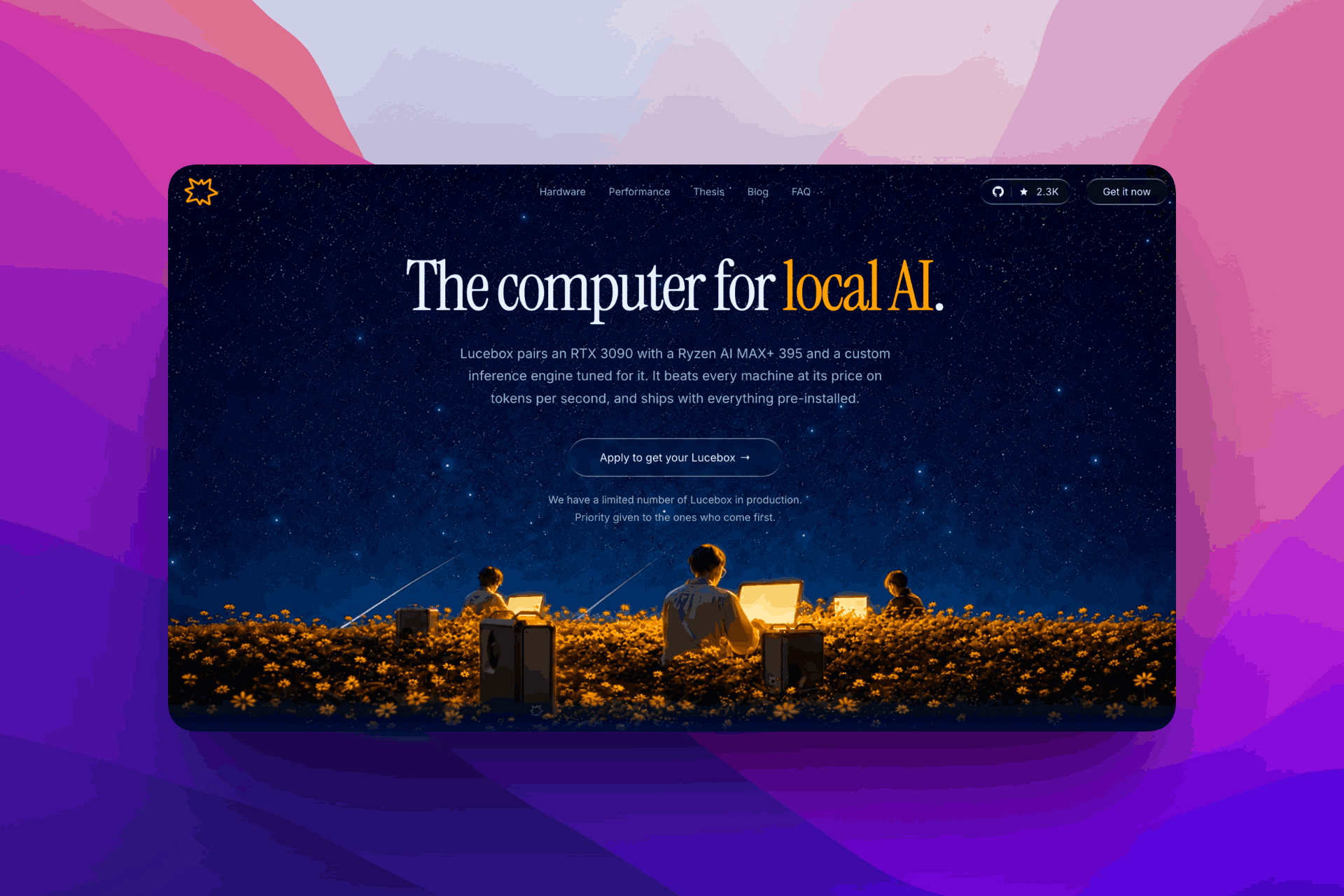
Lucebox is a plug and play computer for teams running local AI inference instead of sending every request to the cloud. It pairs an RTX 3090 with a Ryzen AI MAX+ 395, 128 GB unified memory, and custom CUDA kernels, then exposes local endpoints for tools that speak OpenAI or Anthropic APIs. It ships pre loaded, pairs over Bluetooth, and is built for a July 2026 first production batch.
Why Lucebox works
A normal local AI setup makes the buyer assemble parts, install CUDA, download models, and hope a generic runtime gets close to the hardware's real speed. Lucebox removes that setup gap by shipping the hardware and inference engine as one tuned box, so a team points agents at a local endpoint instead of nursing a workstation into shape.
Lucebox features
- Local inference box. Runs models on the machine, with inference staying on the box and data not leaving by default. Internet is only needed for updates and optional cloud fallback.
- Tuned RTX 3090 setup. Combines a 24 GB GDDR6X RTX 3090 with a Ryzen AI MAX+ 395 and 128 GB LPDDR5X unified memory, so a hot model can stay in VRAM while another sits in unified memory.
- Agent ready endpoints. Works with tools that speak the Anthropic Messages API or OpenAI compatible calls, including Claude Code, OpenCode, Open WebUI, and Ollama.
- Pre loaded setup flow. Pairs over Bluetooth, connects to WiFi, and exposes a dashboard at lucebox.local, with the site claiming about a minute from box to first token.
- Tested before shipping. Every machine is disassembled, repasted, re padded, benchmarked, and pushed through a 72 hour stress test before shipping.
- One year warranty. The full machine is covered for one year, including parts and labor, with repair or replacement for normal use failures.
Who Lucebox is for
- Developers running coding agents who want local tokens without building and tuning their own inference workstation.
- CTOs in regulated industries who need source code, customer data, or patient records to stay inside the building.
- AI teams comparing cloud spend against a fixed hardware cost for repeated local model runs.
- Companies ordering multiple units that want priority selection and shipping for a limited first production batch.
Similar micro SaaS ideas you can build
- Local AI test bench for software teams. A shared appliance for engineering teams that runs repeatable model benchmarks against their own prompts and codebase, so model swaps are tested locally before they touch production workflows.
- Offline AI box for secure field offices. A pre configured AI machine for clinics, legal offices, and government contractors that need drafting, summarizing, and code help in places where cloud tools are blocked or too risky.
- Private endpoint manager for coding agents. A developer tool that gives every coding agent on a team a local model endpoint, usage rules, and fallback settings, so agent traffic goes to owned hardware before paid cloud APIs.